Real time Summary for Live Streams
A system design overview of our real-time summarization service for an ed-tech platform, enabling instant insights form live-streamed lectures.

In September 2024, we were approached by a young ed-tech startup with a need for real-time summarization of live-streamed lectures. They had three key requirements:
Instant transcriptions for live streams.
Real time summaries.
Low infrastructure costs.
Problems
Unlike traditional summarization, where a video is transcribed and then summarized as a batch process, real-time summarization presents unique challenges:
Continuous Data Stream: Live streams generate a constant flow of video data, requiring a system that can process and summarize information on the fly.
Low Latency: The summarization process must operate in real time without introducing noticeable delays for viewers.
High Computation: Processing live audio, generating transcriptions, and summarizing text in real time requires significant resources.
Cost Efficiency: Designing an optimized infrastructure that balances performance and cost.
Solution

The crux of the solution lies within the system architecture. It is not the AI models that are optimized for live stream summarization. But, rather the system architecture that solves the above problems
Job Queue
Before explain the system architecture. Let me first explain what is a job queue since we are using 3 of those in our solution. It is our in house simplified version of Apache Kafka.
It provides 2 major features:
Act as a buffer Queue
Introduce parallelism
Lets understand it with an example:
Consider “Job Queue - 1” in the above diagram.
The incoming stream must be transcoded into different bit rates (1080p, 720p, 480p, etc) in order to serve clients with different bandwidths.
FFmpeg is used for transcoding. It requires some time to process the incoming live stream, which is nothing but a stream of video chunks.
When a video chunk is already being processed by FFmpeg Job Queue acts as a buffer for the other incoming video chunks.
It also introduces parallelism as shown in the image below.

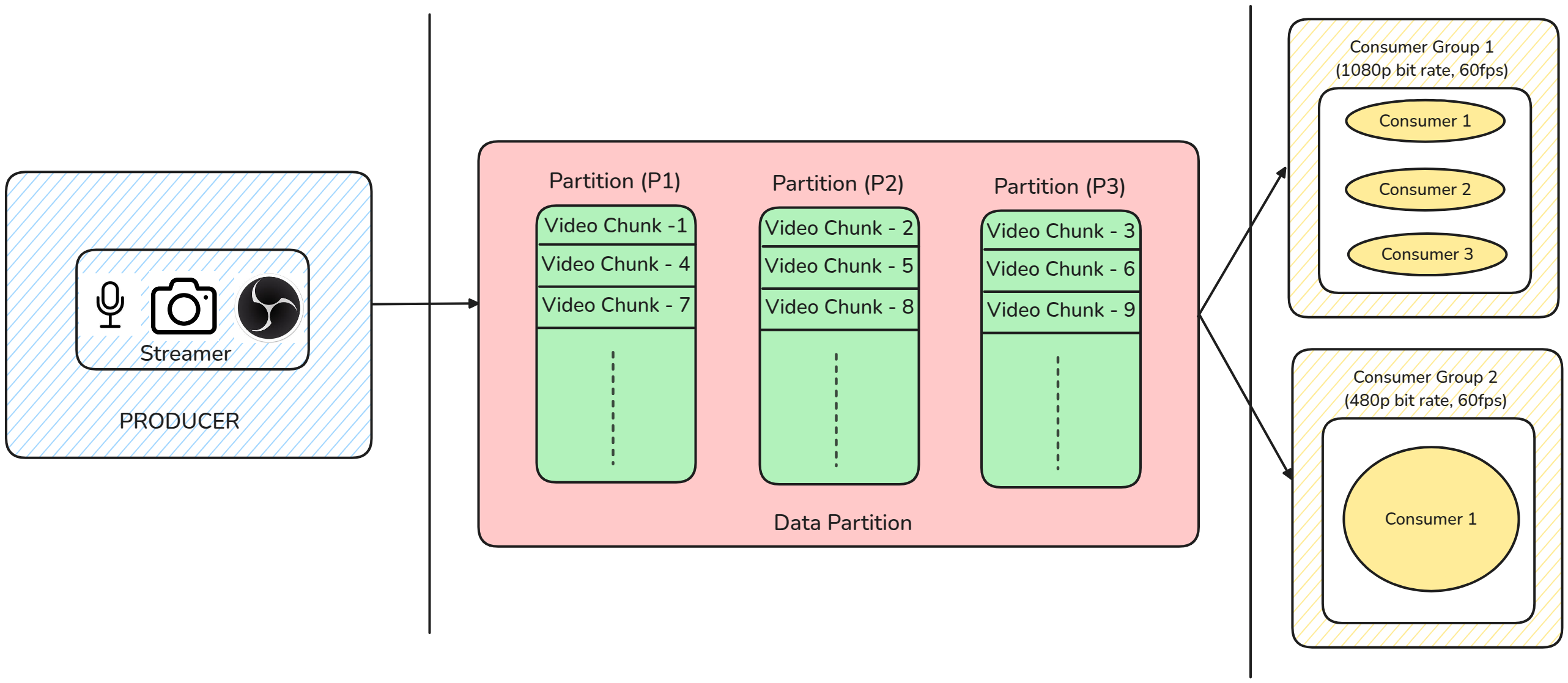
The streamer produces content and it is stored in partitions. There are different Consumer Groups (each for different bit rates). These consumer groups transcode the incoming stream into different bit rates parallely. Each consumer group can have n number of consumers.
Consumer Group 2: Has 1 consumer. So all the partitions are consumed by the single consumer.
Consumer Group 1: Has 3 consumers. So each partition is consumed by a different consumer in parallel. You can call it “nested parallelism”.
These Job Queues are used in 3 places:

Video Transcoding: The example we just saw.
Whisper: Whisper is an AI audio to text encoder-decoder. Audio chunks are partitioned and they are parallely processed into transcriptions.
Gemma: it is an Large Language Model takes these transcriptions and generates summaries.
Paralley computing heavy tasks using job queue makes our solution real time in actual sense.
“Job Queue” solves our first two problems: Instant transcriptions and Real time summaries for live lectures.
Caching
The final problem about Cost Efficiency is simply solved by caching. Generating transcriptions from audio and summaries from those transcriptions is computationally expensive. However, for a single live stream, these outputs remain the same for all viewers. Instead of processing them separately for each client, we generate them once and serve subsequent requests from the cache, significantly reducing computational overhead and infrastructure costs. No rocket Science here!
Thank you so much for reading.
If you found it valuable, hit the ❤️ button.
If you have any questions or suggestions, leave a comment.
Great read.